
This is the second part of an Artificial Intelligence (AI) Series. The first part focused on what is AI and what kind of technologies and techniques are used to build one.
What problem are we solving with artificial intelligence?
We don’t build these robots just because they are interesting and fun. AI is being used for a number of reasons, from medical diagnosis to summarising large amounts of text.
ChatGPT is a game changer because it is so generic. We ask a question and we get an answer that is at the very least a little above average. From my experience, it fails to go deeper into an answer or to solve more complex requests. ChatGPT is still extremely valuable to speed up work and some research.
Let’s look at an AI that is less impressive, on the surface.
Elicit is an AI focused on scientific research and once we ask a question what we get back is a literature review that saves days of human work. It delivers a summary of the top 4 papers and for each search result a summary of the abstract.
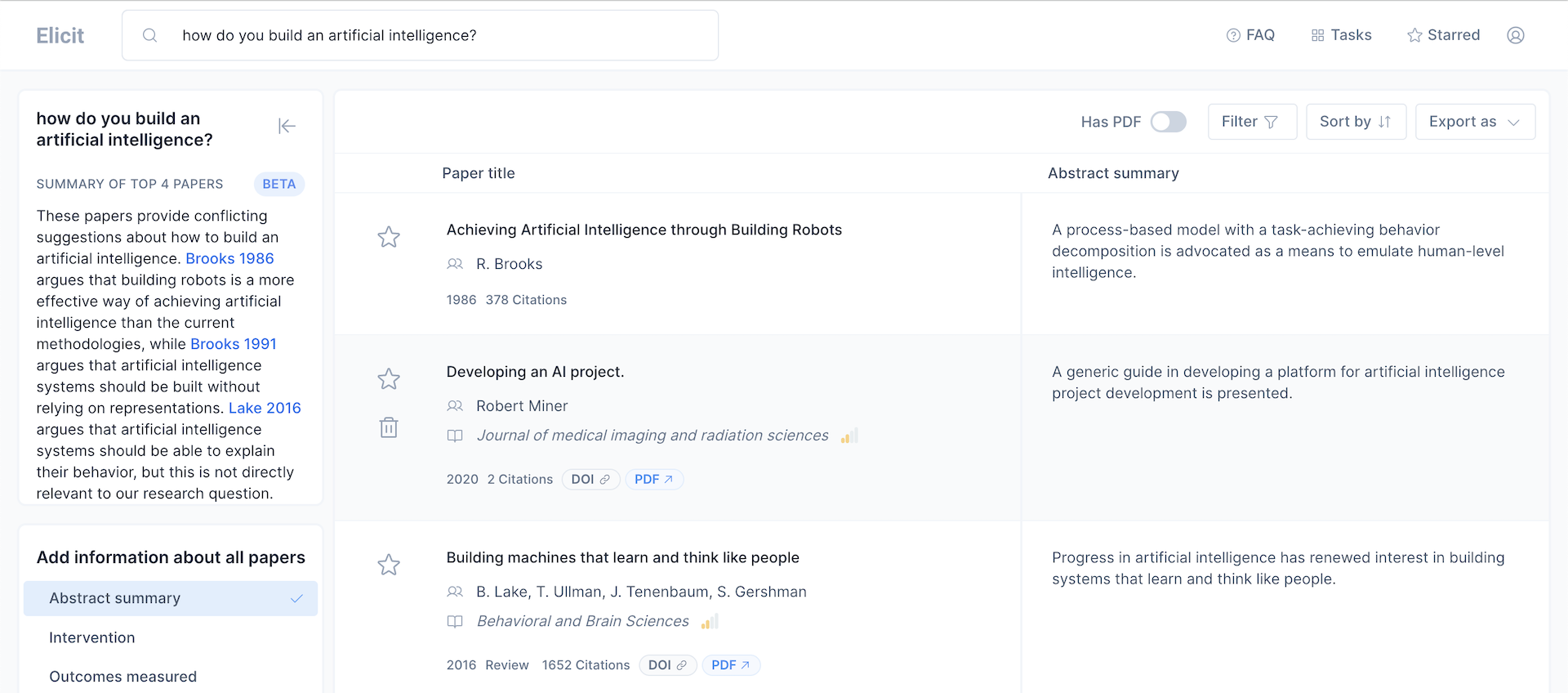
From the start we see the biggest difference between ChatGPT and Elicit. The latter shows the sources of information. It’s not a black box and it’s purpose is focused.
If we’re forming opinions & making decisions based on web search results, we need to be able to judge the credibility of sources. Conversational UI can make results seem more authoritative than is appropriate.
Kim Goodwin on Twitter. She is a consultant and the author of Designing for the Digital Age.
It’s very clear that Elicit’s data comes from the scientific community. The sources of information are displayed and accessible for us to go deeper into the details.
What about ChatGPT ? What if we want to generate images?
The problem in training an AI
DALL-E and Stable Diffusion (SD) both use Neural Networks and required a large ammount of initial images. For SD we know that the initial dataset was LAION-5B, available on laion.ai. It contains 5,85 bilion images and respective text describing each one. The site clearly states that it’s an uncurated collection. It contains sensitive content and almost certainly copyrighted material.
For ChatGPT the initial training dataset brings a new world of questions. Jill Walker Rettberg, professor of digital culture at the University of Bergen, wrote a very clear explanation on the bias around the AI.
“ChatGPT is multilingual but monocultural, and it’s learning your values”
The main takeaway is that the system used an immense dataset, but one that is skewed towards the English language, Christian values, and other forms of bias. Another important point is that humans helped review the dataset. This doesn’t mean the human review was bad, it just highlights that it is necessary.
We don’t know where the answer comes from when we ask ChatGPT to explain a concept. Did it read it on wikipedia? Are there any renowned books to back up the answer?
Feeding the AI with curated content is essential to ensure we get good answers from it. Otherwise, it’s “Garbage in, garbage out”.
It’s also a problem of transparency and validity. We live in the time of Fake News and misinformation and getting answers from a single black box is a problem.
Is academic knowledge enough to train an AI ?
Elicit does a much better job extracting the knowledge from the search results and give us the means to make informed decisions. But as far as I can tell from the website there isn’t a human review, apart from the publishing of science papers.
Is our current corpus of knowledge in scientific journals credible enough to for an AI to deliver good results ?
It depends on our goal. For Elicit’s way of working and purpose of delivering a good literary review, it’s more than enough. it’s up to the researcher using the Eliciti AI to continue the analysis and extract knowledge from all that information.
But the world of scientific publication faces obstacles of it’s own, one of which is the replication crisis. The podcast You Are Not So Smart has an episode explaining the replication crisis in the field of psychology. In short, researchers of all fields can’t always replicate the studies. The problem is worse when we are missing data from the original paper.
James Somers from The Atlantic goes into detail on how the science paper is obsolete, and from my reading there are tools mentioned that could aliviate the replication crisis. If you want to follow that rabbit hole, read Jupyter, Mathematica, and the Future of the Research Paper by Paul Romer.
These arguments are in regard to the quantity of information in the initial datasets and they are enough of a problem to hinder our trust in AI. Other arguments can be made in regards to the quality of information.
The scientific publishing industry faces obstacles to ensure they publish valuable research.
- P-Hacking, when researchers collect data favourable to their findings. Similar to cherry-picking data;
- Importance Hacking, making research seem more relevant than it really is;
- Confirmation Bias, when we publish only papers where the hypothesis is confirmed;
- and more.
Further on we will look into a way to mitigate the problem with datasets based on scientific journals.
Let’s takeaway two main points from this post.
- Ideally, AI should be built with a clear purpose in mind. A field of knowledge, or a task for example.
- The quality of the AI depends on the quality of information we can give it. And right now that raises questions about our scientific knowledge and inherent bias of public datasets
At the moment comments aren’t working, but you can always comment on Mastodon or any other channel, and I’ll share your feedback here. https://mastodon.social/@brunoamaral
